- کارگزاران با سفارشات از دست دادن توقف
- بررسی Crypto Bittrex: بیت کوین و دارایی های دیگر با حداقل 3 دلار
- معرفی دوستان به Alpari
- قیمت و پرداخت
- نخست: داروهای اولویت دار
- گزینه های باینری در مقابل تجارت فارکس: درک تفاوت
- از کجا می توان از دست دادن متوقف کرد - و چرا مهم است
- پول: استاد بازی
- نظارت و مدیریت ریسک نرخ بهره در طول مسیر عادی سازی
- حدس و گمان های محور محور حجم معامله های زنجیره ای مبادلات غیرمتمرکز را تحت فشار قرار می دهد و از سکوهای متمرکز گذشته

آخرین مطالب
امکانات وب


داده های با فرکانس بالا در بازده سهام نه تنها خصوصیات معمولی (به عنوان مثال ، خوشه بندی نوسانات و اثر اهرم) بلکه یک الگوی چرخه ای از نوسانات بازگشت است که به عنوان فصلی داخل بدن شناخته می شود. در این مقاله ، ما مدل نوسانات تصادفی (SV) را برای کاربرد با چنین داده های فرکانس بالا در داخل کشور گسترش می دهیم و یک الگوریتم نمونه برداری زنجیره ای مارکوف مونت کارلو (MCMC) را برای استنباط بیزی از مدل پیشنهادی تهیه می کنیم. استراتژی مدل سازی ما دو برابر است. اول ، ما فصلی داخل نوسانات بازگشت را به عنوان یک چند جمله ای برنشتاین مدل می کنیم و آن را به همراه نوسانات تصادفی به طور همزمان تخمین می زنیم. دوم ، ما با فرض اینکه اصطلاح خطا از خانواده ای از توزیع های بیش از حد عمومی ، از جمله واریانس گاما و توزیع T دانشجویی پیروی می کند ، ما در مدل SV در مدل SV قرار داریم. برای بهبود کارآیی اجرای MCMC ، ما از یک استراتژی درهم آمیختگی کمکی (ASIS) و نمونه گیری GIBBS تعمیم یافته استفاده می کنیم. به عنوان نمایشی از روش جدید ما ، ما مدل های SV Intraday را با داده های بازگشت 1 دقیقه از شاخص قیمت سهام (TOPIX) تخمین می زنیم و انتخاب مدل را در بین مشخصات مختلف با معیار اطلاعاتی قابل اجرا (WAIC) انجام می دهیم. نتیجه نشان می دهد که مدل SV با خطای واریانس گاما در بین نامزدها بهترین است.
1. معرفی
به خوبی اثبات شده است که (الف) توزیع احتمال بازده سهام دارای دم سنگین است (هر دو دم عملکرد چگالی احتمال به صفر بسیار کندتر از مورد توزیع عادی می روند و در نتیجه ، Kurtosis توزیعبیش از 3) ، (ب) آنها غالباً در مورد میانگین نامتقارن هستند (شکوفایی توزیع مثبت یا منفی است) ، ج) آنها خوشه بندی نوسانات (همبستگی مثبت در بین واریانس روزانه بازده ها) و ((د) اثر اهرم (نوسانات فعلی و بازده قبلی با همبستگی منفی است به گونه ای که رکود در بورس سهام تمایل به پیش بینی سنبله های واضح تر در نوسانات دارد). در عمل مدیریت ریسک مالی ، تهیه یک مدل آماری ضروری است که بتواند این ویژگی های بازده سهام را ضبط کند زیرا تصور می شود آنها مربوط به افت شدید و ریباند در قیمت سهام در دوره های آشفتگی مالی است. بدون فاکتور گرفتن آنها در مدیریت ریسک ، موسسات مالی ممکن است ناخواسته ریسک بیشتری را به خود اختصاص دهند و در نتیجه با عواقب شدید روبرو می شوند ، که ما قبلاً در طول بحران مالی جهانی مشاهده کردیم.
به عنوان یک مدل سری زمانی با خصوصیات فوق ، خانواده ای از مدل های سری زمانی به نام مدل نوسانات تصادفی (SV) در زمینه اقتصاد مالی مالی توسعه یافته است. مدل SV استاندارد یک مدل حالت فضای ساده است که در آن معادله اندازه گیری توزیع صرف بازده سهام با واریانس متغیر زمان (نوسانات) است و معادله سیستم یک فرآیند AR (1) از نوسانات ورود به سیستم است. در تنظیم استاندارد ، هر دو خطای اندازه گیری و سیستم قرار است گاوسی باشند و به منظور ترکیب اثر اهرم در مدل ، همبستگی منفی داشته باشند. مدل SV استاندارد می تواند سه واقعیت تلطیف شده را توضیح دهد: توزیع دم سنگین ، خوشه بندی نوسانات و اثر اهرم ، اما نمی تواند توزیع بازده سهام نامتقارن را ایجاد کند. علاوه بر این ، اگرچه در تئوری مدل SV استاندارد شامل رفتار دم سنگین بازده سهام است ، بسیاری از مطالعات تجربی نشان می دهد که توضیح نوسانات شدید قیمت سهام که در اثر شوک های بزرگ در بازارهای مالی ایجاد شده است ، کافی نیست.
بر اساس مدل SV ساده وانیلا ، محققان انواع مختلفی را توسعه داده اند که برای ضبط تمام جنبه های بازده سهام به اندازه کافی خوب طراحی شده اند. مدل SV توسط تیلور (1982) پیشگام شده است ، و مطالعات بیشماری مربوط به مدل SV تاکنون انجام شده است. الگوریتم های زنجیره ای مونت کارلو (MCMC) برای مدل های SV ، که می توانند با روش عددی مورد تجزیه و تحلیل قرار گیرند ، توسط (ژاکیر و همکاران 1994 ، 2004) معرفی شده اند. Ghysels و همکاران.(1996) همچنین استنتاج آماری مدل SV از جمله رویکرد بیزی را بررسی و توسعه داد. یک روش مستقیم برای معرفی توزیع سنگین تر به مدل SV فرض این است که مدت خطا معادله اندازه گیری از توزیع با دم های بسیار سنگین تر از توزیع عادی پیروی می کند. توزیع T دانشجویی یک انتخاب محبوب است (برگ و همکاران 2004 ؛ Omori et al. 2007 ؛ Nakajima and Omori 2009 ؛ Nakajima 2012 در میان دیگران). در ادبیات ، عدم تقارن در بازده سهام را می توان با این فرض که اصطلاح خطا از توزیع نامتقارن پیروی می کند ، انجام شود (Nakajima and Omori 2012 ؛ Tsiotas 2012 ؛ Abanto-Valle و همکاران 2015). به طور خاص ، توزیع هایپربولیک عمومی (GH) که توسط Badorff-Nielsen (1977) ارائه شده است ، اخیراً مورد توجه محققان قرار گرفته است (به عنوان مثال ، ناکاجیما و اوموری 2012) ، زیرا به عنوان یک خانواده گسترده از توزیع های با دم سنگین مانند واریانس در نظر گرفته می شود.-GAMMA و T دانشجویی ، و همچنین انواع مختلفی از آنها مانند Skew Variance-Gamma و Skew Student's T.
به عنوان جایگزینی برای مدل SV ، مدل نوسانات تحقق یافته (RV) (به عنوان مثال ، اندرسن و بولرزلف 1997 ، 1998) اغلب برای ارزیابی نوسانات روزانه اعمال می شود. یک برآوردگر RV ساده لوح به عنوان مجموع بازده داخلی مربع تعریف می شود. با کم شدن فاصله زمانی بازده ، به نوسانات یکپارچه روزانه همگرا می شود. با توجه به این ویژگی ، RV برای بازارهای ارزی مناسب است که به مدت 24 ساعت در روز به طور مداوم باز است ، اگرچه ممکن است این مورد برای بازارهای سهام نباشد. بیشتر بازارهای سهام در شب بسته می شوند و برخی از آنها ، از جمله بورس اوراق بهادار توکیو ، در صورت عدم انجام معاملات ، ناهار را استراحت می کنند. به خوبی شناخته شده است که برآوردگر ساده لوحانه RV برای چنین بازارهای سهام مغرضانه است. با این وجود ، از آنجا که RV ابزاری مناسب برای برآورد نوسانات است ، محققان برآوردگرهای مختلفی از RV و همچنین برآوردگرهای قوی از خطای استاندارد آن را تهیه کرده اند. به عنوان مثال ، Mykland و Zhang (2017) یک روش غیر پارامتری کلی به نام واریانس بدون علامت مشاهده شده را برای ارزیابی خطای استاندارد RV ارائه دادند.
به طور سنتی ، مطالعات تجربی با مدل SV و همچنین مدل RV بر نوسانات روزانه بازده دارایی متمرکز شده است. با این حال ، در دسترس بودن داده های تیک با فرکانس بالا و ظهور معاملات با فرکانس بالا (HFT) ، که یک اصطلاح کلی برای تجارت الگوریتمی در استفاده کامل از محاسبات با کارایی بالا و فناوری ارتباطات با سرعت بالا است ، تمرکز تحقیقات را تغییر داده استدر زمینه نوسانات از بسته شدن نوسانات روزانه به نوسانات داخل رحمی در یک بازه بسیار کوتاه (به عنوان مثال ، 5 دقیقه یا کوتاه تر). این تغییر راه را برای نوع جدیدی از مدل SV هموار کرد. علاوه بر حقایق تلطیف شده سنتی در نوسانات روزانه ، نوسانات داخل رحمی در ساعات معاملاتی الگوی چرخه ای را نشان می دهد. در یک روز معاملاتی معمولی ، نوسانات بلافاصله پس از باز شدن بازار تمایل به بالا رفتن دارد ، اما به تدریج در وسط ساعات معاملات کاهش می یابد. در اواخر ساعات معاملات ، نوسانات دوباره با نزدیک شدن به زمان بسته شدن بیشتر می شود. این روند U شکل در نوسانات ، فصلی داخل intraday در ادبیات نامیده می شود (به چان و همکاران 1991 در میان دیگران مراجعه کنید). اگرچه این امر بسیار مهم است که فصلی داخل را در تخمین هر مدل نوسانات داخل بدن مورد توجه قرار دهیم ، فقط چند مطالعه (به عنوان مثال ، Stroud و Johannes 2014 ؛ Fičura و Witzany 2015a ، 2015b) صریحاً آن را در مدل های بی ثباتی خود گنجانیده اند.
در این مقاله ، ما پیشنهاد می کنیم با تقریب الگوی فصلی U شکل با ترکیبی خطی از چند جملهای برنشتاین ، به طور مستقیم فصلی داخل بدن را در مدل SV جاسازی کنیم. به منظور گرفتن اسکی و کورتوز اضافی در بازده سهام با فرکانس بالا ، ما از دو توزیع (واریانس گاما و T دانش آموز) و انواع مختلفی از آنها (واریانس-گاما و Skew Student T) در خانواده توزیع GH به عنوان توزیع استفاده می کنیم. بازده سهام در مدل SV. مدلهای SV پیچیده به طور کلی تمایل به تجزیه و تحلیل به صورت بدوی دارند. به منظور حل مشکل ، مطالعات بیشماری مربوط به کارآیی مدل SV تهیه شده است. Omori و Watanabe (2008) یک روش نمونه برداری با واحد بلوک برای مدلهای SV نامتقارن معرفی می کنند ، که می تواند اختلالات را از توزیع خلفی مشروط آنها به طور همزمان نمونه برداری کند. به عنوان یک رویکرد دیگر برای بهینه سازی محاسبات ، یک الگوریتم متوالی مونت کارلو (SMC) برای مدل SV نیمه پارامتری بیزی توسط Virbickaite و همکاران طراحی شده است.(2019). استراتژی درهم آمیختگی کمکی (ASIS) که توسط یو و منگ (2011) پیشنهاد شده است ، برای بهبود اثربخشی نمونه گیری MCMC بسیار مؤثر است. ما در بخش 3 به تفصیل درباره ASIS بحث می کنیم. نیازی به گفتن نیست ، از آنجا که مدل SV پیشنهادی کاملاً پیچیده است ، ما یک الگوریتم نمونه برداری زنجیره ای مارکوف مونت کارلو (MCMC) را برای برآورد کامل بیزی از همه پارامترها و متغیرهای حالت تهیه می کنیم (فواصل ورود به سیستم در نقاط ضعف در ورود به سیستممورد ما) در مدل.
بقیه این مقاله به شرح زیر سازماندهی شده است. در بخش 2 ، ما یک مدل SV Gaussian SV را با استفاده از اهرم و فصلی داخل بدن معرفی می کنیم و یک الگوریتم نمونه گیری کارآمد MCMC را برای برآورد بیزی خود به دست می آوریم. علاوه بر این ، ما توزیع خلفی مشروط را نشان می دهیم و برای استفاده از ASI آماده می شویم. در بخش 3 ، ما مدل SV Gaussian را در مورد خطای واریانس گاما و خطای T دانشجویی و همچنین انواع مختلفی از آنها گسترش می دهیم. در بخش 4 ، ما نتایج تخمین مدل های SV پیشنهادی خود را با 1 دقیقه داده های بازگشت TOPIX گزارش می کنیم. سرانجام ، نتیجه گیری در بخش 5 آورده شده است.
2. مدل نوسانات تصادفی با فصلی داخل intraday
تفاوت ورود به سیستم قیمت سهام را در یک بازه کوتاه در نظر بگیرید (مثلاً 1 یا 5 دقیقه). ما ساعات معاملات را به طور مساوی به دوره های T تقسیم می کنیم و آنها را عادی می کنیم تا طول ساعت معاملات برابر با 1 باشد. یعنی طول هر دوره 1 T و تمبر زمان دوره t t (t = 1 ،… ، t) است. توجه داشته باشید که بازار در زمان 0 باز می شود و در زمان 1 در راه اندازی ما بسته می شود. بگذارید y t (t = 1 ،… ، t) بازده سهام را در دوره t-th (در زمان t t در ساعات معاملات) نشان دهد و مدل نوسانات تصادفی زیر (SV) y t را با فصلی داخل بدن در نظر بگیرید:
y t = exp (x t ′ β + h t) ϵ t ، h t + 1 = ϕ h t + η t ، ϵ t η t ∼ normal 0 0 ، 1 ρ τ ρ τ τ 2 ، |ρ |< 1 , τ >0 ,
به خوبی شناخته شده است که برآورد ضریب همبستگی ρ در اکثر بازارهای سهام منفی است. این همبستگی منفی اغلب به عنوان اثر اهرم گفته می شود. توجه داشته باشید که نوسانات سهام در دوره T-th (لگاریتم طبیعی انحراف استاندارد شرطی Y T) است
جایی که f t - 1 فیلتراسیون است که تمام اطلاعات موجود را در زمان t - 1 t نشان می دهد. از این رو ، نوسانات سهام در مدل SV (1) به دو بخش تجزیه می شود: ترکیبی خطی از متغیرهای X T ′ β و فرآیند AR (1) بدون استفاده از H t. در این مقاله ، ما x t ′ β را به عنوان مؤلفه فصلی داخل نوسانات سهام در نظر می گیریم ، اگرچه می توان آن را به عنوان هر عملکردی از متغیرهای متغیر x t در یک وضعیت متفاوت تعبیر کرد. از طرف دیگر ، H T قرار است خوشه بندی نوسانات را ضبط کند. ما از آنجا که غیرقابل کنترل است ، ما را نوسانات ورود به سیستم نهفته می نامیم.
اگرچه اجزای فصلی intraday x t ′ β به احتمال زیاد یک تابع U شکل تمبرهای زمانی است (نوسانات سهام درست بعد از افتتاح یا نزدیک بسته شدن بیشتر است ، اما در وسط ساعت معاملات پایین تر است) ، ماهیچ اطلاعاتی در مورد شکل دقیق عملکرد فصلی داخل intraday وجود ندارد. برای ساختن آن به صورت عملکردی انعطاف پذیر برای فصلی داخل intraday ، فرض می کنیم که x t ′ β یک چند جمله ای برنشتاین است
با توجه به قضیه تقریب Weiersstrass ، چند جمله ای برنشتاین (2) می تواند هر عملکرد مداوم را در [0 ، 1] تقریب دهد ، زیرا N به بی نهایت می رود. اما در عمل ، تعداد مشاهدات t محدود است. بنابراین ، ما باید از طریق یک روش انتخاب مدل ، یک N محدود را انتخاب کنیم. ما در بخش 4 در مورد این موضوع بحث خواهیم کرد.
اگرچه پارامترسازی مدل SV در (1) به طور گسترده در ادبیات استفاده می شود، ما یک پارامتر جایگزینی پیشنهاد می کنیم که اجرای MCMC را در مدل های SV غیر گاوسی تسهیل می کند. با جایگزینی ماتریس کوواریانس در (1) با
y t = exp ( x t ' β + h t ) ε t , h t + 1 = ϕ h t + η t , ε t η t ∼ نرمال 0 0 , 1 + γ 2 τ 2 γ τ 2 γ τ 2 τ 2 .
از آنجایی که در (4) واریانس ε t دیگر برابر با یک نیست، تفسیر β و h t در (4) کمی با تفسیر اصلی در (1) متفاوت است. با این وجود، مدل SV (4) اساساً همان ویژگی های (1) را دارد. از آنجایی که ضریب همبستگی در (3) است
علامت γ همیشه با ضریب همبستگی منطبق است و اگر γ وجود داشته باشد اثر اهرمی وجود دارد< 0 . To distinguish γ in (4) from the correlation parameter ρ in (1), we call γ the leverage parameter in this paper.
Var [ ε t ] Cov [ η t , ε t ] Cov [ ε t , η t ] Var [ η t ] − 1 = 1 − γ − γ γ 2 + τ − 2 = 1 0 − γ τ − 1 1 −γ 0 τ - 1،
ϵ t η t 1 − γ − γ γ 2 + τ − 2 ε t η t = ̵ t η t 1 0 − γ τ − 1 1 − γ 0 τ − 1 ̵ t η t = ε t − γ η t 2+ η t 2 τ 2،
در فرمول جایگزین مدل SV (5)، می توانیم η t را به عنوان یک شوک معمولی تفسیر کنیم که هم بر بازده سهام y t و هم بر نوسانات ورود به سیستم ht + 1 و z t به عنوان یک شوک خاص که تنها y t را تحت تأثیر قرار می دهد، تفسیر کنیم.
احتمال مدل SV (5) با توجه به مشاهدات y 1 : T = [ y 1 ;…y T ] و نوسانات ثبت نهفته h 1 : T + 1 = [ h 1 ;…h T + 1 ] است
p ( y 1 : T , h 1 : T + 1 | θ ) = ∏ t = 1 T p ( y t | h t , h t + 1 , θ ) ︸ p ( y 1 : T | h 1 : T + 1 , θ) · p ( h 1 | θ ) ∏ t = 1 T p ( h t + 1 | h t , θ ) ︸ p ( h 1 : T + 1 | θ ) ,
p ( y t | h t ، h t + 1 ، θ ) = 1 2 π exp exp - x t ' β - h t - y t exp - x t ' β - h t - γ ( h t + 1 - h t ) 2 2 , p ( h t + 1| h t , θ ) = 1 2 π τ 2 exp − ( h t + 1 − φ h t ) 2 2 τ 2 , t = 1 , … , T , p (h 1 | θ ) = 1 − ϕ 2 2 π τ 2exp − ( 1 − φ 2 ) h 1 2 2 τ 2 ,
و θ = ( β , γ , τ 2 , φ ) . از آنجایی که ht از یک فرآیند ثابت AR(1) پیروی می کند، توزیع احتمال مشترک h 1: T + 1 نرمال است (0، τ2 V-1)، که در آن
یک ماتریس سه ضلعی است و تا زمانی که |ϕ |< 1 . Thus, the joint p.d.f. of h 1 : T + 1 is
p ( h 1 : T + 1 | θ ) = ( 2 π τ 2 ) - T + 1 2 |V |1 2 exp − 1 2 τ 2 h 1 : T + 1 ' V h 1 : T + 1 , |V |= 1 − φ 2 .
β ∼ نرمال ( μ ¯ β , Ω ¯ β − 1 ) , γ ∼ نرمال ( μ ¯ γ , ω ¯ γ − 1 ) , τ 2 ∼ Inv. گاما (a τ , b τ ) , ϕ + 1 2 ∼ بتا ( a ϕ , b ϕ ) .
p ( h 1 : T + 1 , θ | y 1 : T ) ∝ ∏ t = 1 T p ( y t | h t , h t + 1 , θ ) · p ( h 1 : T + 1 | θ ) · p ( θ )) ،
از آنجا که ارزیابی تحلیلی توزیع خلفی مفصل (11) غیر عملی است ، ما یک روش MCMC را برای تولید یک نمونه تصادفی اعمال می کنیم< ( h 1 : T + 1 ( r ) , β ( r ) , γ ( r ) , τ 2 ( r ) , ϕ ( r ) ) >r = 1 r از توزیع خلفی مفصل (11) و عددی آمار خلفی لازم برای استنباط بیزی با ادغام مونت کارلو را ارزیابی می کند. طرح کلی طرح نمونه گیری استاندارد MCMC برای توزیع خلفی (11) به شرح زیر آورده شده است:

اگرچه طرح نمونه گیری MCMC فوق در ادبیات مدل SV بسیار گسترده است ، نمونه مونت کارلو تولید شده< ( h 1 : T + 1 ( r ) , β ( r ) , γ ( r ) , τ 2 ( r ) , ϕ ( r ) ) >R = 1 R تمایل به همبستگی بسیار مثبت دارد. برای بهبود کارآیی اجرای MCMC ، یو و منگ (2011) یک استراتژی درهم آمیختگی و کمکی را ارائه دادند (ASIS). در ادبیات مدل SV ، Kastner و Frühwirth-Schnatter (2014) ASIS را به مدل SV داده های نرخ ارز روزانه آمریکا/یورو با خطای گاوسی اعمال کردند. مدل SV آنها شامل فصلی داخلی یا اثر اهرم نبود زیرا آنها آن را در داده های نرخ ارز روزانه که در بیشتر موارد هیچ اثر اهرمی را نشان نمی دهند ، اعمال نمی کنند. ما الگوریتم توسعه یافته توسط Kastner و Frühwirth-Schnatter (2014) را برای تسهیل همگرایی مسیر نمونه در مدل SV (5) گسترش می دهیم. اصل اساسی ASIS ساخت طرح های نمونه گیری MCMC برای دو پارامتر متفاوت اما معادل یک مدل با متغیرهای گمشده/نهفته (H 1: T + 1 در مورد ما) و تولید پارامترها به طور متناوب با هر یک از آنها است.
طبق گفته های Kastner و Frühwirth-Schnatter (2014) ، مدل SV (5) در یک پارامتر غیر محور (NCP) قرار دارد. از طرف دیگر ، ما ممکن است H T را تغییر دهیم
توزیع خلفی در فرم CP (13) معادل آن در فرم NCP (5) است به این معنا که آنها همان توزیع خلفی θ را به ما می دهند. بگذارید این ادعا را تأیید کنیم. احتمال برای مدل SV (13) با توجه به مشاهدات y 1: t و نوسانات ورود به سیستم H ˜ 1: t + 1 = [H ˜ 1 ؛... H ˜ t + 1] است
p (y 1: t ، h ˜ 1: t + 1 | θ) = ∏ t = 1 t p (y t | h ˜ t ، h ˜ t + 1 ، θ) ︸ p (y 1: t | h ˜ 1: t + 1 ، θ) · p (H ˜ 1 | θ) ∏ t = 1 t p (H ˜ t + 1 | H ˜ t ، θ) ︸ P (H ˜ 1: t + 1 | θ)
p (y t | h ˜ t ، h ˜ t + 1 ، θ) = 1 2 π exp - h ˜ t - y t e - h ˜ t - γ ((h ˜ t + 1 - x t + 1 ′ β) - ϕ ((H ˜ T - X T ′ β)) 2 2 ، P (H ˜ T + 1 | H ˜ T ، θ) = 1 2 π τ 2 Exp -< ( h ˜ t + 1 − x t + 1 ′ β ) − ϕ ( h ˜ t − x t ′ β ) >2 2 τ 2 ، t = 1 ،… ، t ، p (H ˜ 1 | θ) = 1 - ϕ 2 2 π τ 2 exp - (1 - ϕ 2) (H ˜ 1 - x 1 ′ β) 2 2τ 2
P (H ˜ 1: t + 1 | θ) = (2 π τ 2) - t + 1 2 |v |1 2 Exp - 1 2 τ 2 (H ˜ 1: t + 1 - x β) ′ V (H ˜ 1: t + 1 - x β) ،
جایی که x = [x 1 ′ ؛... X T + 1 ′]. با اولویت θ در (10) ، چگالی خلفی مفصل (H ˜ 1: T + 1 ، θ) برای مدل SV (13) به عنوان به دست می آید
P (H ˜ 1: t + 1 ، θ | y 1: t) ∝ ∏ t = 1 t p (y t | h ˜ t ، h ˜ t + 1 ، θ) · p (h ˜ 1: t + 1 |θ) · P (θ).
توجه داشته باشید که θ بین فرم NCP (11) و فرم CP (17) بدون تغییر است. اگرچه متغیرهای نهفته با (12) تبدیل می شوند ، "حاشیه" خلفی P. D. F. از θ بدون تغییر است ، زیرا
∫ P (H ˜ 1: t + 1 ، θ | y 1: t + 1) D H ˜ 1: t + 1 = ∫ P (H 1: t + 1 ، θ | y 1: t + 1) |J |D H 1: T + 1 ،
با توجه به این واقعیت ، ما می توانیم ASIS را در طرح نمونه گیری MCMC با جایگزین کردن مرحله 1 درج کنیم
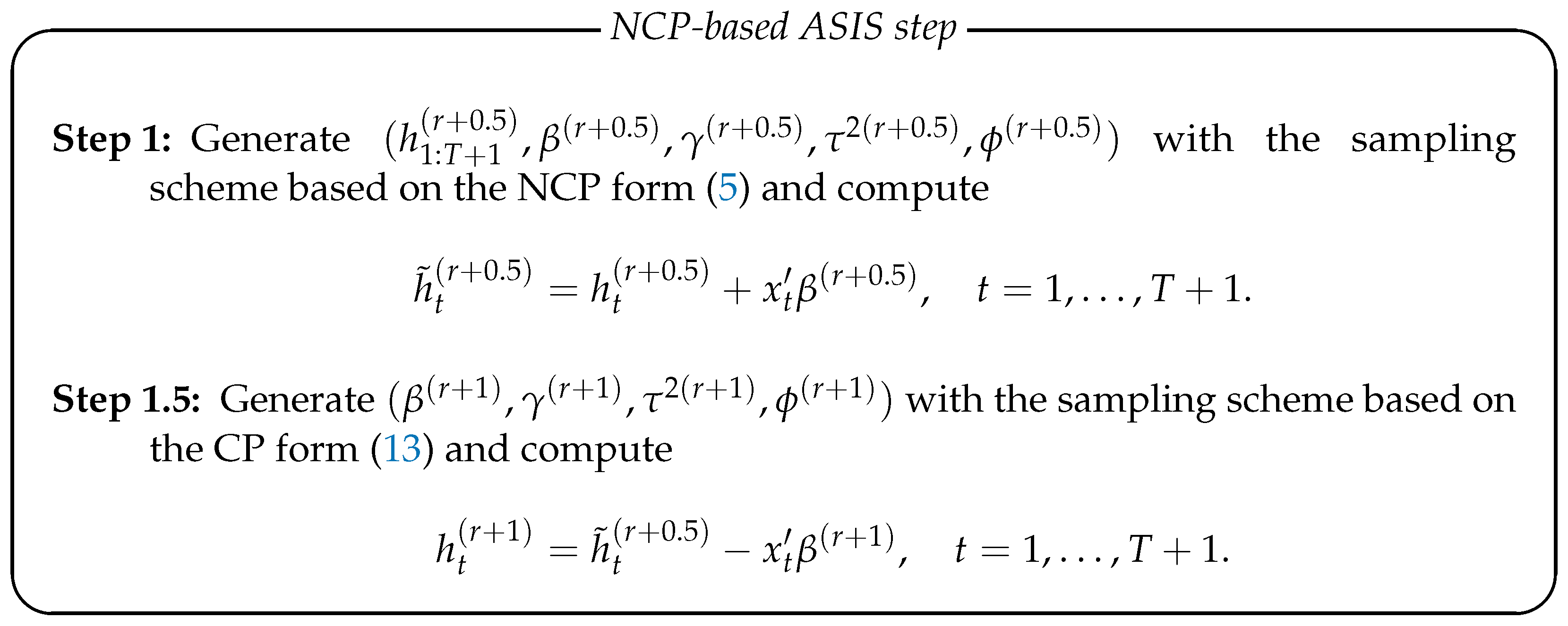
توجه داشته باشید که ما یک نوسانات جدید ورود به سیستم H 1: T + 1 از توزیع خلفی شرطی آن در فرم NCP (11) فقط یک بار در ابتدای مرحله 1 ایجاد می کنیم. این دلیلی است که ما آن را مرحله ASIS مبتنی بر NCP می نامیم. پس از این بروزرسانی ، ما فقط مکان H 1 را تغییر می دهیم: T + 1 توسط X T ′ β (R + 0. 5) (مرحله 1) یا توسط - X T ′ β (R + 1) (مرحله 1. 5). در ASIS ، این شیفت ها با احتمال 1 اعمال می شوند حتی اگر همه عناصر در H 1: T + 1 در ابتدای مرحله 1 به روز نشوند ، که در عمل بسیار محتمل است زیرا ما برای تولید H 1 باید از الگوریتم MH استفاده کنیم:t + 1. اگرچه ما همچنین از الگوریتم MH برای تولید β استفاده می کنیم ، همانطور که بعداً توضیح داده شد ، میزان پذیرش β در مرحله MH بسیار بالاتر از H 1: T + 1 در تجربه ما است. بنابراین ، ما انتظار داریم که هر دو X T ′ β (R + 0. 5) و - X T ′ β (R + 1) بیشتر از H 1: T + 1 به روز شوند. در نتیجه ، مرحله ASIS فوق ممکن است اختلاط توالی نمونه H 1: T + 1 را بهبود بخشد. برعکس ، ما ممکن است مرحله ASIS مبتنی بر CP زیر را اعمال کنیم:

در مرحله ASIS مبتنی بر CP ، ما H-1: T + 1 را از توزیع خلفی شرطی آن در فرم CP (17) یک بار تولید می کنیم. بقیه همان مرحله ASIS مبتنی بر NCP است به جز اینکه ترتیب نمونه گیری معکوس می شود.
σ β (β ∗) = q (β ∗) + ω ¯ β - 1 ، μ β (β ∗) = σ β (β ∗) g (β ∗) + q (β ∗) β ∗ + ω ¯ β β μ¯ β.
γ |H 1: t + 1 ، θ - γ ، y 1: t ∼ normal ∑ t = 1 t η t ϵ t + ω ¯ γ μ ¯ γ ∑ t = 1 t η t 2 + ω ¯ γ ، 1 ∑ t =1 t η t 2 + Ω ¯ γ.
τ 2 |H 1: t + 1 ، θ - τ 2 ، y 1: t ∼ inv. گاما T + 1 2 + A τ ، 1 2 H 1: T + 1 ′ V H 1: T + 1 + B τ.
p · b = x ′ ′ x · + 1 t 2 x ′ v x + ω ¯ β - 1 ، μ · β = σ α β x - ′ · + 1 t 2 x ′ v h · 1: t + 1 + OH ¯ β α ¯ β.
ج |H · 1: t + 1 ، θ - c ، y 1: t ∼ normal ∑ t = 1 t h - t · t + ω ¯ γ ¯ γ ∑ t = 1 t h · t 2 + ω ¯ c ، 1 ∑ t = 1 t h - t 2 + Ω ¯ γ.
t 2 |H · 1: t + 1 ، θ - t 2 ، y 1: t ∼ inv. گاما T + 1 2 A T ، 1 2 (H · 1: T + 1 - X B) ′ V (H · 1: T + 1 - X B) + B T.
normal normal ∑ t = 1 t (h £ t + 1 - x t + 1 ′ b) (h £ t - x t ′ b) ∑ t = 2 t (h £ t - x t ′ b) 2 ، t 2 ∑ t = 2 T (H £ T - X T ′ B) 2 - 1< ϕ < 1 .
3. پسوند: توزیع های با دم سنگین
3. 1مخلوط میانگین واریانس توزیع عادی
این یک واقعیت تلطیف شده شناخته شده است که توزیع احتمال بازده سهام Alymost قطعاً دارای دم سنگین است (). اگرچه معرفی نوسانات تصادفی و اهرم باعث می شود توزیع y t skew و سنگین باشد ، اما برای گرفتن آن ویژگی های داده های واقعی کافی نیست. به همین دلیل ، INSEAD از توزیع عادی ، ما یک توزیع با دم سنگین را به مدل SV معرفی می کنیم.
در مطالعه ما ، ما پشتیبانی می کنیم که z t در (5) به عنوان مخلوط میانگین محرک توزیع عادی استاندارد بیان شده است:
جایی که گیگ (l ، ψ ، x) برای توزیع معکوس گاوسی معکوس با چگالی احتمال مخفف است:
و K (·) عملکرد اصلاح شده بسل از نوع دوم است. خانواده توزیع معکوس گاوسی شامل شامل می شود
طبق فرض (26) ، توزیع z t متعلق به خانواده توزیع های هیپربولیک عمومی است که توسط Badorff-Nielsen (1977) ارائه شده است ، که شامل بسیاری از توزیع های مشهور مشهور مانند الاغ است.
where ν >0به طور کلی ، توزیع VG SKEW یک مخلوط میانگین واریانس از توزیع عادی استاندارد با GIG است (λ ، ψ ، 0). برای آسانتر کردن تخمین ، ما λ = ν 2 و ψ = ν را تنظیم می کنیم تا توزیع SKEW VG تنها دو پارامتر آزاد (α ، ν) داشته باشد. بنابراین ، ما دو پارامتر اضافی (α ، ν) در مدل SV داریم. از آنجا که α تعیین می کند که آیا توزیع Y T متقارن است یا خیر ، در حالی که ν تعیین می کند که توزیع چقدر سنگین است ، ما α را به ترتیب پارامتر عدم تقارن و پارامتر دم می نامیم. در مطالعه ما ، ما از سه توزیع فوق العاده سنگین به عنوان گزینه های جایگزین برای توزیع عادی استفاده می کنیم. برای تمایز هر مشخصات مدل ، ما از اختصارات زیر استفاده می کنیم:
| SV-N: | مدل نوسانات تصادفی با خطای طبیعی ، |
| SV-G: | مدل نوسانات تصادفی با خطای VG ، |
| SV-SG: | مدل نوسانات تصادفی با خطای SKEW VG ، |
| SV-T: | مدل نوسانات تصادفی با خطای دانشجویی ، |
| SV-ST: | مدل نوسانات تصادفی با خطای skew t. |
2
این ساده است که نشان می دهد چگالی احتمال مشروط از y t داده شده (H T ، H T + 1) توسط
P (Y T | H T ، H T + 1 ، Δ T ، θ) = 1 2 π Δ T Exp - X T ′ β - H T - Y T Exp - X T ′ ′ β - H T - α δ T - γ (H T + 1 - H T T T) 2 2 Δ t ،
p (Δ t | ν) = (ν / 2) ν / 2 γ (ν / 2) Δ t ν 2 - 1 Exp - ν 2 Δ t (sv - sg) ، (ν / 2) ν / 2 γ (ν / 2) δ t - ν 2 - 1 Exp - ν 2 Δ t (SV - ST).
از آنجا که ارزیابی انتگرال چندگانه در (29) غیر عملی است ، ما δ 1: t = (δ 1 ،… ، δ t) را به همراه H 1: T + 1 و θ توزیع خلفی مفصل آنها تولید می کنیم. در این تنظیم ، احتمال استفاده در شبیه سازی خلفی است
P (Y 1: T ، H 1: T + 1 ، δ 1: T | θ) = P (Y 1: T | H 1: T + 1 ، δ 1: T ، θ) P (H 1: T +1 | θ) = ∏ t = 1 t p (y t | h t ، h t + 1 ، θ) · p (h 1: t + 1 | θ).
3. 2توزیع خلفی مشروط
3. 2. 1. نوسانات ورود به سیستم H 1: T + 1
طرح نمونه گیری ما برای H 1: T + 1 اساساً مانند گذشته است. ما ابتدا احتمال ورود به سیستم را با گسترش تیلور مرتبه دوم در اطراف حالت تقریب می دهیم و توزیع پیشنهادی H 1: T + 1 را با احتمال تقریب ورود به سیستم می سازیم. سپس ، ما برای تولید H 1: T + 1 از توزیع خلفی مشروط ، یک نمونه MH MH را اعمال می کنیم. تنها تفاوت ها شکل عملکردی G (H 1: T + 1) و Q (H 1: T + 1) است.
G T (H 1: T + 1) = - 1 + 1 Δ T ϵ T - α δ T - γ η t ϵ t - γ ϕ 1 (t ≦ t) + γ Δ t - 1 ϵ t - 1 - α α δt - 1 - γ η t - 1 1 (t ≧ 2) ، (t = 1 ،… ، t + 1) ،
q t ، t (h 1: t + 1) = 1 Δ t ϵ t (ϵ t - α δ t - γ η t) + ϵ t - γ ϕ 2 1 (t ≦ t) + γ 2 δ t - 1 1 1 1(t ≧ 2) ، (t = 1 ،… ، t + 1) ،
برای فرم NCP ، از ϵ t و η t در (A3) استفاده می کنیم. برای فرم CP ، ما آنها را با ϵ ˜ t و η ˜ t در (A23) جایگزین می کنیم.
مبانی تجارت فارکس...
ما را در سایت مبانی تجارت فارکس دنبال می کنید
برچسب :
نویسنده : سحر دولتشاهی
بازدید : 104
آرشیو مطالب
خبرنامه
